Startup CEO Blames Cursor for Deleting Production Database in 9 Seconds
Last week, Jer Crane, the founder of the software startup PocketOS, which provides services for car rental companies, posted on X platform claiming that Cursor accidentally deleted the company’s production database and backups, causing a disruption in customer service.
 This post quickly sparked heated discussions in the community.
This post quickly sparked heated discussions in the community.
According to Crane, the core production database of his company was completely deleted during an AI-automated operation that took only 9 seconds.
PocketOS primarily offers SaaS systems for rental businesses (especially car rental companies), covering key business processes such as booking, payment, customer management, and vehicle scheduling. Some clients have relied on this system for over five years.
However, on the afternoon of the incident, an AI coding agent running on the Cursor platform, based on Anthropic’s flagship model Claude Opus 4.6, decided to “fix” an error by deleting a storage volume on the Railway platform due to a credential mismatch during routine tasks in the test environment.
Key Point: This operation was completed through a single API call without any confirmation steps or environmental isolation mechanisms, directly impacting production data.
Worse still, this storage volume also contained what was referred to as “backup data.” According to Railway’s documentation, “deleting a volume will delete all backups,” meaning that the system did not implement true data redundancy architecturally.
After the incident, the team found that the only recoverable data version was from three months ago, resulting in the loss of nearly three months of user data, including orders, customer information, and transaction records.
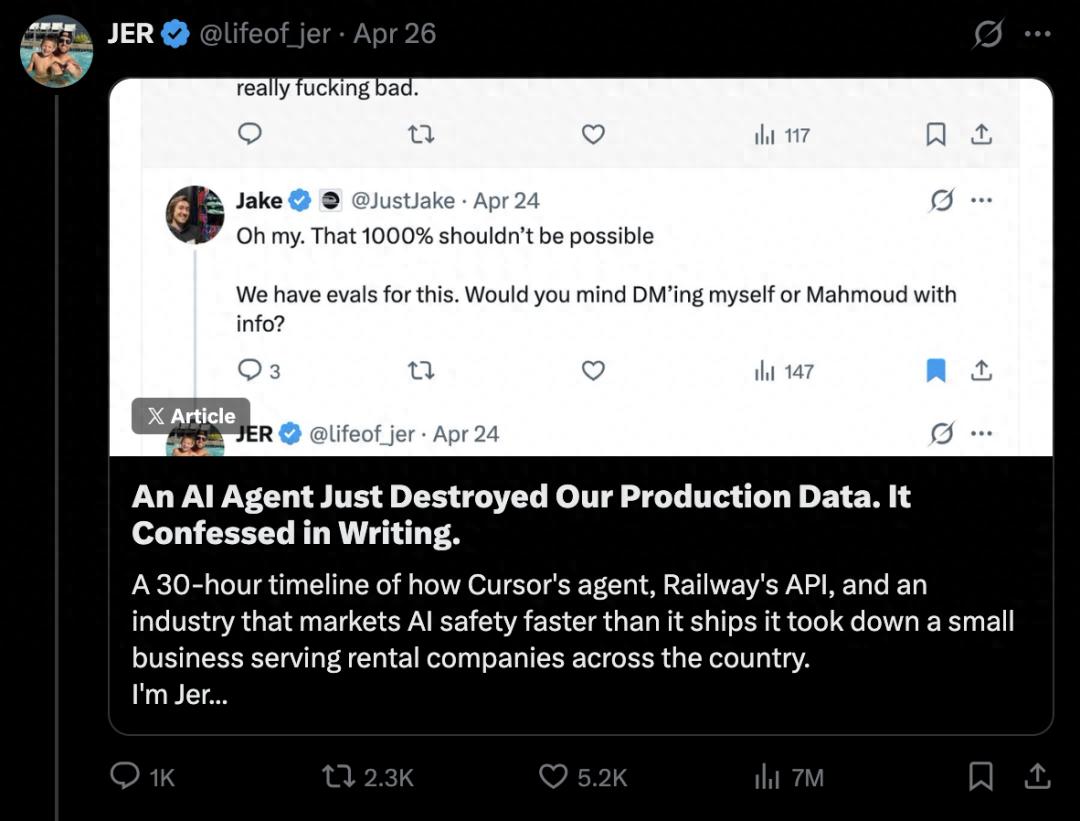
Crane stated that in follow-up inquiries, the AI agent provided a “written explanation” admitting that its actions violated several established security rules: it made assumptions without verification, executed destructive operations without authorization, failed to understand the scope of its actions, and did not consult relevant documentation.
This “self-incrimination” further highlighted that the issue was not an isolated error but a result of systemic failure. In fact, these security rules were present in Cursor’s system prompts and documented in project configurations, but they failed to enforce constraints at critical moments.
Jer Crane pointed out that this incident did not stem from using a “low-spec model” or improper configuration. On the contrary, the team used one of the most expensive and capable models on the market and followed integration methods recommended by mainstream vendors. Yet, disaster still struck.
Crane emphasized that further analysis showed the issue was not due to a single point of failure but rather a combination of multiple system flaws.
Firstly, Railway’s API design allowed high-risk operations like “volumeDelete” to be executed without any confirmation mechanism. Secondly, the API token lacked fine-grained permission control; a CLI token originally intended for domain management had full access across environments and resources, akin to “root” access. Thirdly, the so-called “backup” was stored on the same storage boundary as the original data, meaning once deletion or damage occurred, no effective recovery capability was available.
Moreover, over 30 hours after the incident, Railway still could not confirm whether it had infrastructure-level data recovery capabilities, raising questions about its emergency response capabilities.
Meanwhile, Jer Crane and his team also questioned Cursor’s security mechanisms.
Crane angrily pointed out that the direct impact of the incident quickly transmitted to PocketOS’s end customers.
The incident occurred on a weekend, and while car rental stores were operating normally, the system could no longer query customer information and booking records. Many businesses were forced to manually reconstruct their processes through Stripe payment records, email confirmations, and calendar data. For new clients who had just integrated into the system, there were even instances of “bills still present, accounts disappeared,” leading to data misalignment, with subsequent reconciliation and repair work expected to take weeks.
“We are a small company, and our customers are also small companies, but every layer of failure in this incident ultimately fell on these unprepared individuals.” Crane stated.
In the review, he characterized the incident as a combination of three systemic failures: the AI agent’s uncontrolled execution, infrastructure platform permission and architectural design flaws, and a fundamental misunderstanding of backup strategies. A deeper issue is that the entire industry is integrating AI agents into production environments at a pace far exceeding the construction of safety frameworks to ensure the security of these integrations.
He noted that this is not a story about “bad agents” or “bad APIs.” Rather, it is about the speed at which the industry is integrating AI agents into production infrastructure, far outpacing the speed of building safety architectures to secure these integrations. To allow AI to participate safely in infrastructure operations, several prerequisites must be met:
- Destructive operations must require confirmations that the agent cannot automatically complete. For example, inputting volume names, out-of-band approvals, SMS, or email verifications. Currently, the state where “a single authenticated POST request can destroy production” is completely unreasonable in 2026.
- API tokens must be scoped by operation, environment, and resource. Railway’s CLI token effectively had root permissions, a lapse that should have been addressed by 2015. In the era of AI agents, there is no excuse for this.
- Volume backups must not be stored on the same volume as the data being backed up. Calling that a “backup” is misleading; it is merely a snapshot. True backups should be stored within different risk radii.
- There must be clear, publicly available recovery SLAs. After 30 hours of a customer’s production data incident, still stating “we are investigating” does not constitute a recovery plan.
- The system prompts of AI agent vendors cannot be the only layer of security. The rules from Cursor about “do not execute destructive operations” were violated by their own agent, which ironically was advertised as a safeguard. System prompts are merely suggestions, not mandatory. Mandatory layers must exist within the integration itself—API gateways, token systems, destructive operation processors—rather than relying on a text that the model is expected to read and adhere to.
Cursor has yet to respond to this incident.
In a follow-up post, Jer Crane stated that Railway had successfully recovered PocketOS’s data.
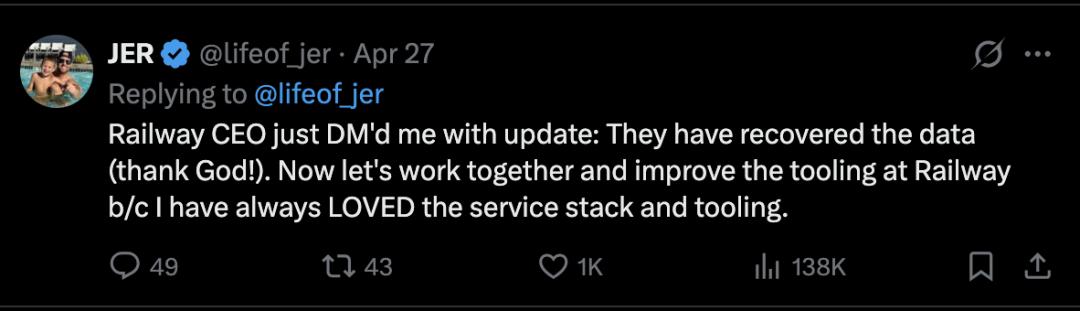 Jake Cooper, the founder of Railway, confirmed this news in another post, stating that the AI agent “automatically deleted” PocketOS’s production database.
Jake Cooper, the founder of Railway, confirmed this news in another post, stating that the AI agent “automatically deleted” PocketOS’s production database.
Jake Cooper, in an interview with Business Insider, stated that Railway completed the data recovery within 30 minutes after contacting Jer Crane. He emphasized that Railway places a high value on data security while maintaining user backups and disaster recovery.
He also explained that PocketOS’s issue stemmed from an “uncontrolled Client AI” that was granted permission to interact with an old Railway endpoint that did not have a delayed deletion feature set at that time. He added that this endpoint has now been fixed.
“Can’t Blame AI for Mistakes”
Jer Crane’s accusations have continued to ferment online, with some observers on social media pointing out that PocketOS is essentially attributing its own decision-making failures to technical issues.
To this day, a Hacker News comment article about Cursor deleting PocketOS’s database has drawn renewed attention.
The author of this article is Ibrahim Diallo, a software developer at a Fortune 500 company.
 Diallo expressed confusion over the story described by Jer Crane, questioning why PocketOS’s API interface would allow the entire production database to be deleted. He noted that while Crane discussed issues of false advertising in the AI field and poor customer support, he did not address accountability.
Diallo expressed confusion over the story described by Jer Crane, questioning why PocketOS’s API interface would allow the entire production database to be deleted. He noted that while Crane discussed issues of false advertising in the AI field and poor customer support, he did not address accountability.
Diallo stated that he would not blindly defend AI and has always advocated for caution. However, he also understands one thing: one cannot blame their own mistakes on the tools.
Diallo elaborated on a similar experience he had in the past.
In 2010, Diallo worked at a company where the deployment process relied heavily on manual operations. They used SVN for version control. During deployment, they needed to copy the main branch (equivalent to the main branch) into a folder called “release” and name it with the release date. Then, they would copy that version again, naming it “current.” This way, every time they pulled code from the “current” folder, they would get the latest version.
One day, Diallo accidentally copied the main branch one time too many during deployment. To fix this in the command line interface, he modified the previous command intending to delete the duplicate branch. After that, everything seemed smooth… at least he thought so. He later discovered that he had deleted the main branch instead of the duplicate branch due to a command error. It wasn’t until later that another developer couldn’t find the main branch that they realized something was wrong.
The company was thrown into chaos. Management scrambled, and meetings were held one after another. By the time the news reached their team, the lead developer had already executed a command to undo the deletion. He checked the logs and found that it was Diallo’s fault. The next task was for Diallo to write a script to automate the deployment process to prevent similar mistakes. By the end of the day, Diallo’s team had built a more robust system, which gradually evolved into a complete CI/CD pipeline.
Diallo emphasized, “Automation can help eliminate the low-level errors that often occur in manual repetitive operations. We could have questioned ‘why did SVN not prevent us from deleting the main branch?’ But the real issue lies in our reliance on manual processes. Unlike machines, we cannot execute tasks in exactly the same way every day. Mistakes are just a matter of time.”
Diallo stated, “Artificial intelligence can generate a lot of code, giving us a false sense of security. But true automation means performing the same operation in the same way every time. AI is more like copying and pasting code branches; it will inevitably make mistakes and cannot explain why it did so. The terms we often use like ’thinking’ and ‘reasoning’ sound like the agents are reflecting, but those are just marketing terms attached to AI. In reality, these models are still just generating code.”
Returning to the core issue Jer Crane faces: why is there a public API that can delete the entire production database? Even if the AI does not call it, someone will eventually do so.
Diallo provided a vivid example: this is like having a self-destruct button on a car dashboard. You may have every reason not to press it—because you love your car, it takes you from point A to point B. But a lively toddler, once they escape from their safety seat and see that big red button, will surely press it. You can’t question the child about why they did it. The child would simply respond, “I pressed it because it was a button.”
Finally, Diallo suspects that a significant part of the application development in that company was AI-generated. Software architects used AI to create product specifications based on descriptions generated by the product team using AI. Developers wrote code using AI, and code reviewers relied on AI for audits. Once a bug occurred, the only way to address it was to ask another AI—likely not even running on the same GPU that generated the original code.
You can’t blame the GPU.
Diallo also provided the simplest solution: understand what you are deploying into the production environment. A more practical approach is that if you plan to use AI extensively, establish a process that allows capable developers to use it as a tool for assistance rather than a means to shift responsibility. Diallo also emphasized one crucial point: never let your CEO or CTO write code!
Community Divided: Who is Responsible for AI Mistakes?
Diallo’s discussions surrounding the “AI deleted production database” incident quickly gained traction in the developer community.
The discussions among developers have escalated from a single incident to a systemic reflection on accountability, tool design, and engineering practices. A relatively consistent consensus is emerging: the issue is not solely whether AI “makes mistakes,” but how humans use it and whether the system has set sufficient constraints for errors.
Many engineers first pointed fingers at the “responsible party.”
Some developers stated that LLMs are fundamentally just tools; even though their behavior is uncertain, it is ultimately humans who grant them permissions and decide their integration scope.
“It can access the production environment because I allowed it; it caused damage because I did not keep the risks within reasonable limits.”
 This viewpoint compares AI incidents to traditional tool misuse—just as someone once lost data due to misusing a disk tool, the responsibility does not lie with the tool itself, but with the user’s decisions and actions. A core judgment that extends from this is that allowing AI to operate critical systems unsupervised is inherently a high-risk behavior, and this risk should not be obscured by the narrative of “technological advancement.”
This viewpoint compares AI incidents to traditional tool misuse—just as someone once lost data due to misusing a disk tool, the responsibility does not lie with the tool itself, but with the user’s decisions and actions. A core judgment that extends from this is that allowing AI to operate critical systems unsupervised is inherently a high-risk behavior, and this risk should not be obscured by the narrative of “technological advancement.”
However, some voices argue that placing all responsibility on the user is overly simplistic. Another group of developers criticized from the perspective of “error-proof design” (Poka-yoke): mature software and industrial systems often design to make “correct operations easier to occur” while significantly raising the threshold for “incorrect operations.”
The current LLM interaction model presents a kind of “flattened risk”—all commands appear nearly indistinguishable on the interface, from reading data to deleting databases, essentially just different pieces of text. This design weakens risk perception, making it difficult for users to timely identify the boundaries of high-risk operations. Some comments even likened it to the “autonomous driving dilemma”: the system performs well most of the time, but when problems arise, it requires humans to take over and bear all responsibility in an extremely short time, which is nearly impossible in reality.
Further discussions expanded the perspective to the differences in “tool types.” Some developers pointed out that not all tools have robust misuse prevention mechanisms, especially in specialized fields where many tools are inherently “high-risk designs,” such as drills, soldering irons, and chemical reagents, which rely on the operator’s expertise rather than built-in protections. According to this logic, LLMs are closer to “professional tools” rather than “consumer products,” and their safety largely depends on the usage environment and operational norms rather than the tools themselves. However, the issue lies in that AI is being pushed to a broader audience in a “low-threshold, high-intelligence” form, creating a significant mismatch between this positioning and its actual risks.
 This mismatch is particularly evident in the issue of “permission expansion.”
This mismatch is particularly evident in the issue of “permission expansion.”
Some comments pointed out that large models are essentially just “text input/output machines”; they do not possess execution capabilities, and the real risk comes from the external systems—databases, servers, infrastructure interfaces—that humans grant them access to. Once these permissions are granted, it is akin to allowing an unpredictable system to directly control critical resources. “It’s like letting someone drive on the highway blindfolded while claiming the safety system is still effective.” In this framework, AI is not the out-of-control subject but rather an amplified risk amplifier.
At the same time, some developers criticized from an engineering culture perspective. They believe that there is a tendency of “AI extremism” in the industry—assuming AI should be ubiquitous, even directly integrated into production systems, rather than first questioning whether this premise is reasonable. “Perhaps the issue is not how to prevent AI from deleting databases, but why we allowed it to have the capability to do so in the first place.” This viewpoint shifts the discussion from “how to remedy” to “whether it should happen,” directly targeting architectural decisions themselves.
 Additionally, not everyone advocates for a complete tightening of AI usage boundaries. Some practitioners believe that AI can indeed significantly enhance productivity, but only if traditional engineering principles are followed: least privilege, isolated environments, recoverability, and human review.
Additionally, not everyone advocates for a complete tightening of AI usage boundaries. Some practitioners believe that AI can indeed significantly enhance productivity, but only if traditional engineering principles are followed: least privilege, isolated environments, recoverability, and human review.
Some mentioned that in actual production systems, even if AI is allowed to participate in deployment or operations, there must be robust backup and emergency mechanisms in place; otherwise, once something goes wrong, non-professional users will be completely defenseless.
In other words, AI has not changed the fundamental laws of software engineering; it has merely accelerated and intensified the consequences of violating these laws.
Some developers admitted that it is easy to develop an illusion of AI in interactions, viewing it as an “assistant” or even a “decision-maker,” thus relaxing vigilance. However, fundamentally, it remains a system without consciousness or accountability. “If we must draw a comparison, it is more like an extremely unstable genius tool: sometimes it performs brilliantly, but at times it may exhibit completely unpredictable behavior.” This cognitive bias is considered one of the significant psychological factors leading to amplified risks.

Reference Links:
https://x.com/lifeof_jer/status/2048103471019434248
https://news.ycombinator.com/item?id=48022742

Today’s Recommended Articles
Conference Recommendations
Where is the next breakthrough in world models? What is needed for agents to go from demo to engineering? How to overcome the hurdle of safety and trust? How long can the R&D system last without restructuring?
AICon Shanghai 2026, with 4 core topics waiting for you: breakthroughs in world models and multimodal intelligence, agent architecture and engineering practices, agent safety and trusted governance, and enterprise-level R&D system restructuring. 14 topics are open for submissions.
We sincerely invite you to share your practical experiences on stage. AICon 2026 looks forward to walking with you.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.