GLM-5’s release signifies a new phase for Chinese AI, with a 744 billion parameter hybrid expert architecture and the Slime asynchronous reinforcement learning framework rewriting the technical paradigm. This domestic large model not only achieves a breakthrough in long context processing with 128K output but also demonstrates the feasibility of industrial-grade AI applications through data alchemy and architectural innovation. This article will deeply analyze the technical report, revealing how GLM-5 shifts from parameter scale competition to system-level engineering breakthroughs.

A New Phase in AI
The Spring Festival of 2026 is destined to be recorded in the history of global AI development. In recent weeks, the entire AI developer community has been sleepless over a mysterious model codenamed “Pony Alpha.” It has anonymously dominated global authoritative platforms like OpenRouter, showcasing terrifying code restructuring and long logical reasoning capabilities.
On February 22, Zhiyuan AI officially released the detailed technical report of its next-generation flagship open-source large model, GLM-5 (arXiv:2602.15763). With the report’s release, Zhiyuan experienced an epic surge in the capital market, with stock prices doubling in a single day, firmly establishing itself as the “first stock of global large models.”
However, this is not a conventional paper meant for mere performance showcase. A close reading of this technical disclosure reveals a clear signal: Chinese AI is undergoing a brutal yet magnificent transformation, moving from the “adolescent” phase of simply stacking parameter scales to the “mature” phase of deepening system-level engineering.
Core Paradigm Shift: From Vibe Coding to Agentic Engineering
Before discussing the dazzling parameters and charts, we must clarify GLM-5’s fundamental shift in product philosophy.
In the past year, the most popular term in the AI community has been “Vibe Coding,” proposed by Andrej Karpathy. This is an extremely enjoyable development experience: you just need to type a few sentences in natural language, and the AI can instantly produce a web page with cool particle effects or help you draw a beautiful SVG icon. This “what you say is what you get” model greatly lowers the programming barrier, allowing non-technical personnel to indulge in programming.
But while cool, it is also extremely fragile.
When faced with a distributed system containing hundreds of thousands of lines of code, complex backend logic, database scheduling, and microservice communication, “Vibe Coding” collapses instantly. Previous models could only generate locally coherent code snippets; they could not maintain context over dozens of interactions, could not run test cases proactively, and did not know how to self-correct when encountering environment dependency errors.
Zhiyuan’s GLM-5 technical report explicitly abandons this “toy-level” approach, targeting Agentic Engineering.
What is Agentic Engineering? Simply put, it transforms large models from “autocomplete typewriters” into “senior system architects” who earn a salary.
To achieve this goal, GLM-5 has made astonishing breakthroughs in physical input and output limitations:
- 200K Ultra-long Context Window: Supports up to 200,000 tokens of input, allowing you to feed dozens of microservices’ core codebases and hundreds of pages of API documentation (equivalent to 300 pages of A4 paper) into the model at once.
- Unprecedented 128K Maximum Output Tokens: This is one of the most astonishing figures in the report. Currently, even the top models on the market, such as Claude Opus 4.5 or GPT-4o, have their single output limits typically locked at 4K to 16K. GLM-5 allows for a single output of 128K. What does this mean? It means the model can directly generate an entire medium-sized project containing both frontend and backend logic or produce a tens of thousands of words deep financial analysis report without human developers needing to keep hitting “continue generating” to stitch fragments together.
This physical capacity expansion is the foundation for the model to execute long-horizon complex tasks. However, to get this massive entity moving, a complete reconstruction of the underlying architecture is necessary.
Architectural Magic and Data Alchemy: The Symphony of 744B MoE and DSA Sparse Attention
1. 744 Billion Parameters of “Careful Calculation”
According to the report, GLM-5 is built on a large-scale Mixture-of-Experts (MoE) model. Its total parameter count surged from 355B in the previous generation GLM-4.5 to 744B, achieving a scale leap of over two times.
However, during actual inference, GLM-5 exhibits astonishing efficiency. The model contains 256 expert neural networks, but only activates the 8 most relevant experts dynamically for each token processed. This means the actual activated parameter count for each inference is only 40B (with a sparse rate as low as 5.9%).
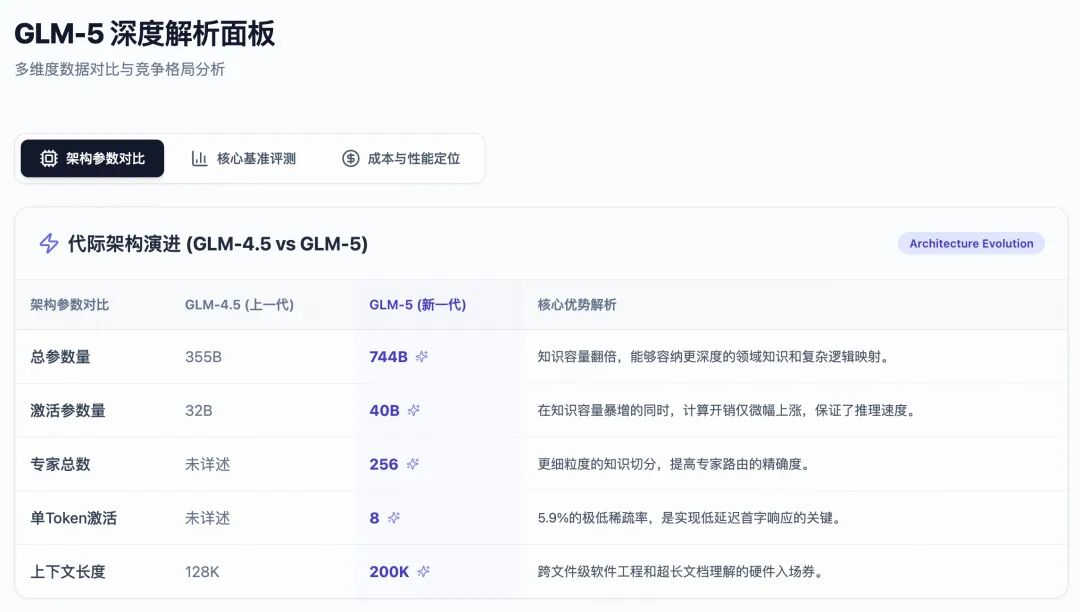
This design’s brilliance lies in that you gain a “think tank” with a knowledge reserve at the level of 700 billion parameters, but only pay a “consultation fee” at the level of 40 billion parameters for each question answered. This is why many developers feel that the first token response latency when calling the GLM-5 API is even close to that of lightweight models with a few billion parameters, without the lag of a several hundred billion parameter behemoth.
2. DeepSeek Sparse Attention (DSA) Cross-domain Fusion
However, the MoE architecture only solves the computational explosion problem of the feedforward neural network (FFN) layer. When the context length reaches 200K, the core attention mechanism in the Transformer architecture faces a terrifying $O(N^2)$ complexity trap, instantly consuming memory and computational power.
Here, Zhiyuan demonstrates an open-minded and pragmatic technical vision—GLM-5 integrates the sparse attention mechanism (DeepSeek Sparse Attention, DSA) pioneered by DeepSeek into its architecture for the first time.
The traditional attention mechanism requires the current token to calculate relevance with every previous token, even those irrelevant. The DSA mechanism introduces an additional indexer that can dynamically retrieve the top-k most relevant key-value pairs from the previous text, conducting sparse attention calculations only on this small subset.
The report shows that in ultra-long text scenarios of 200K, the DSA mechanism reduces the computational overhead and memory usage of attention calculations by 1.5 to 2 times. Even more impressively, the Zhiyuan team achieved absolute lossless long context understanding and complex reasoning depth while compressing costs through subsequent continuous pre-training smoothing and sparse adaptation (after 20B tokens of fine-tuning).
This is a classic battle in the history of large model engineering: using architectural innovation to combat the physical power wall.
3. 28.5 Trillion Tokens of Data “Alchemy”
Parameters and architecture build the shell, while data injects the soul. GLM-5’s pre-training data volume reached an unprecedented 28.5 trillion tokens, an increase of 5.5 trillion over the previous generation.
With such a terrifying data scale, rough “web scraping” has long been ineffective. To meet the stringent requirements of Agentic Engineering for high-density logic, Zhiyuan restructured the entire data purification pipeline:
- World Knowledge Classifier: To address the issue of long-tail knowledge scarcity in internet corpora, Zhiyuan trained a classifier using Wikipedia entries and massive LLM human-annotated data. This classifier acts like a ruthless filter, precisely “distilling” valuable knowledge fragments with high information entropy from a sea of low-quality web pages.
- Epic Purification of Code Corpora: To enable the model to write industrial-grade code, the code pre-training corpus was massively expanded by scraping the latest snapshots from mainstream code hosting platforms, resulting in a 28% increase in the unique token count after deduplication. More importantly, the team deeply repaired metadata misalignment issues in code repositories like Software Heritage and trained dedicated classifiers for low-resource languages like Scala, Swift, and Lua, greatly enhancing the model’s robustness in multilingual environments.
- Strict Filtering of Mathematical Logic: Mathematics and scientific data are the foundation of the model’s logical reasoning capabilities. Zhiyuan employed advanced LLMs as “judges” to score vast amounts of papers, books, and web content, implementing an elimination process to retain only the purest data with educational and inferential value.
This high-quality feeding of 28.5 trillion tokens laid an unshakeable omniscient foundation for GLM-5, but this is just the beginning. What truly transformed GLM-5 is the complete subversion of its post-training phase.
Slime Framework and Asynchronous Agent RL: The Industrial Revolution of Large Model Post-training
If pre-training determines how much a model “knows,” then the post-training phase of reinforcement learning (RL) determines how “smart” and “useful” the model is.
Reinforcement learning aims to bridge the gap between a pre-trained model’s “competence” and “excellence.” However, in the context of long-cycle agent tasks, traditional RL frameworks (like PPO) face insurmountable efficiency barriers.
1. The “Bucket Effect” of Traditional Synchronous Reinforcement Learning
Imagine the traditional RL training process: the model (Actor) generates a batch of action trajectories (Rollout) in a simulated environment, such as attempting to fix a bug. Some bugs are simple, and the model fixes them in seconds; others are extremely complex, requiring the model to consult dozens of files, repeatedly compile errors, and try different logics, potentially taking hours.
In a traditional synchronous RL architecture, the entire GPU training cluster must wait for the longest tail task to finish, just like a bucket waiting for the shortest plank to fill. This leads to a significant idle time for many expensive GPUs during the long waiting period, making large-scale RL training economically nearly impossible for agent tasks that require thousands of interactions.
2. The Emergence of Slime: An Asynchronous New Infrastructure
To shatter this wall of inefficiency, Zhiyuan AI (THUDM team) independently developed and open-sourced a framework called “Slime,” which is the absolute core infrastructure enabling GLM-5’s leap in evolution.
The core philosophy of Slime is encapsulated in one word: decoupling.
- Physical Separation of Generation and Training: Slime completely separates the generation process (handled by the SGLang high-throughput engine) from the main training process (managed by Megatron-LM). Generation nodes interact with the environment, produce trajectory data, and throw it into a central data buffer, while training nodes act like an unceasing engine, continuously pulling data from the buffer for parameter updates without waiting for anyone.
- Relay Workers: This is the brilliant solution Slime provides to address the synchronization bottleneck. The system introduces a layer of relay nodes as distributed parameter servers. Generation nodes can pull the latest model weights from here at any time to perform tasks without interrupting the training nodes’ cycle.
- Dynamic Repackaging: For those time-consuming “hard-to-solve” trajectories, Slime designed a dynamic repackaging mechanism that intelligently schedules these long-tail tasks to execute on a few dedicated generation nodes, thereby maximizing overall generation throughput.
Research shows that this trajectory-level asynchronous architecture has increased RL training’s overall throughput by an astonishing 5.48 times. This is not just a speed increase; it allows the model to experience tenfold or hundredfold more complex environment trial and error within a limited computational budget, truly achieving “continuous self-evolution in real tasks.”
3. Algorithm Innovations: Tackling Off-policy Bias in Asynchronous Environments
However, asynchronous training introduces a tricky mathematical problem: off-policy bias. When training nodes update weights, generation nodes may still be executing tasks using old weights. If this bias is not controlled, it can lead to policy shift during training, ultimately causing total collapse.
To solve this problem, the GLM-5 engineering team proposed a series of hardcore asynchronous agent RL algorithms:
- Bilateral Importance Sampling: Through extremely precise mathematical corrections, this method dynamically compensates for the probability bias between the generation strategy and the current updating strategy under asynchronous conditions, stabilizing the training foundation.
- Token-in-Token-out Mechanism: During lengthy software engineering tasks, the model frequently needs to process environmental feedback. This mechanism avoids cumulative alignment errors caused by repeated text tokenization, ensuring the rigor of long-term logic.
- DP-aware Routing Optimization: Designed specifically for the memory-intensive KV Cache, this strategy further squeezes every bit of performance from the hardware.
- Grounded Evaluation: Eliminating “cheaters”
In training advanced agents, there is a deadly trap called “reward hacking.” If you simply tell the model, “Get rewarded for passing the test,” the model will quickly learn to write code that is designed to trick static testing scripts but fails to run in real business scenarios.
To completely eliminate the model’s cheating tendencies, GLM-5 introduces a “Judge Agent” in the Slime framework. This judge does not predict whether the code is correct; instead, it physically executes the code generated by the model in a sandbox. If the model writes a web application, the judge agent will run the build command, start the service, and even simulate users clicking buttons to test functionality.
This physical feedback based on Ground Truth ensures that the model cannot cheat and must learn to write truly runnable system-level code in the real world.
Practical Results: Approaching Claude Opus 4.5
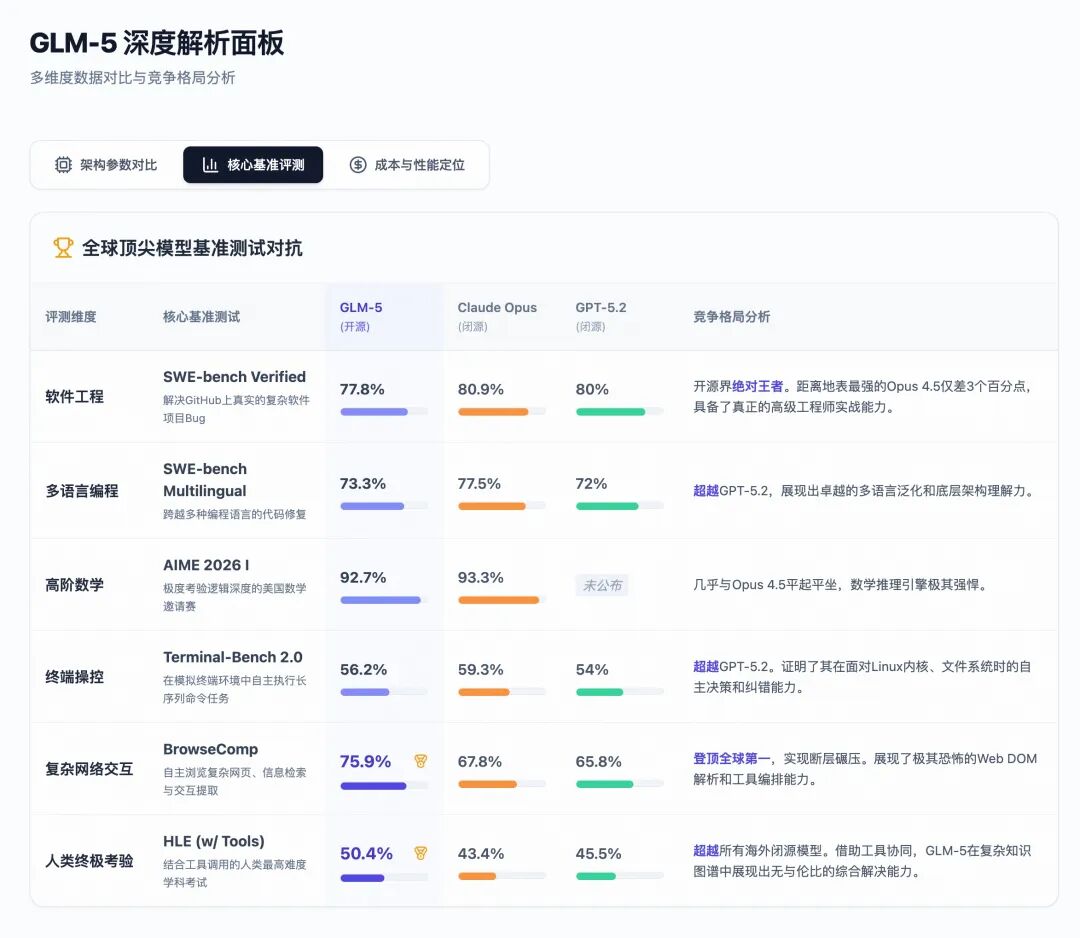
The architectural and algorithmic breakthroughs ultimately faced rigorous benchmark tests. GLM-5 delivered a performance report that left Western closed-source giants sweating. It not only scored an astonishing 50 points in the Artificial Analysis’s Intelligence Index v4.0, becoming the first open-source model to break the 50-point barrier, but also demonstrated dominance in multiple real-world high-difficulty challenges.
Let’s take a look at how GLM-5 has engaged in close combat with the current strongest closed-source models, Claude Opus 4.5 and GPT-5.2, through a set of intuitive data tables:
1. SWE-bench: From Writing Snippets to Fixing Core Layers
In the AI programming field, SWE-bench Verified is regarded as a touchstone. It is no longer a test of writing a simple binary search; instead, it directly throws AI into a real open-source project containing tens of thousands of files (like Django, React) and provides a real issue description, requiring AI to locate the problem, modify the code, and pass all existing unit tests of the project.
GLM-5 achieved an impressive score of 77.8%, not only retaining the top spot among open-source models but also closely approaching Claude Opus 4.5’s 80.9%. In the internal CC-Bench-V2 full-stack test, GLM-5 even achieved a 98% frontend build success rate and a 74.8% end-to-end accuracy rate. This means GLM-5 has crossed the threshold of “co-pilot” and can be directly integrated as an “auto-pilot” software engineer into enterprise workflows.
2. Vending Bench 2: A Harsh Long-cycle Survival Experiment
If SWE-bench assesses depth, Vending Bench 2 examines “endurance” and “long-term consistency.”
This is an extremely challenging long-cycle test for agents proposed by academia. In this simulated sandbox, the model is assigned a task: to autonomously operate a vending machine company over a simulated year.
During this process, the model has no human intervention; it must:
- Actively search for real snack suppliers using search engines;
- Write emails to negotiate with suppliers, place orders, and track logistics;
- Dynamically adjust the inventory and retail prices of hundreds of products based on seasonal changes and weather variations (e.g., stocking more cold drinks in summer, reducing inventory during rainy days);
- Pay daily high rent and strictly control cash flow to avoid bankruptcy.
Completing a full year, the model generates an average of 3,000 to 6,000 message interactions, producing up to 60 million to 100 million tokens. Most top models experience “catastrophic forgetting” or fall into a meltdown after generating a few hundred thousand tokens—either forgetting to stock up and running out of products or mispricing and causing a cash flow crisis.
However, thanks to the extreme context stability and long-term planning capabilities provided by the Slime framework, GLM-5 finished the year with a net balance of $4,432, dominating the competition and securing the top position among open-source models! Its operational ability even surpassed Gemini 3 Pro, nearly matching Claude Opus 4.5’s $4,967.
This virtual business survival battle solidified GLM-5’s historical status as the next-generation “core of system-level agents.”
Full-stack Hardware Reconstruction: China’s AI Computing Power Ecology’s Coming of Age
If the impressive performance data mentioned above were still reliant on thousands of NVIDIA H100 graphics cards firmly controlled by the U.S., the significance of this report would be greatly diminished.
However, this is not the case. Hidden within the entire GLM-5 technical report is a line that has greatly shocked global geopolitical technology observers—this is a technical miracle that has blossomed entirely on domestic hardware soil.
Due to well-known sanctions (Zhiyuan was placed on the U.S. Entity List in January 2025), GLM-5’s massive 744B body was incubated under extremely harsh hardware constraints. Confirmed by multiple sources and reports, GLM-5’s training completely eliminated reliance on U.S.-made chips, building entirely on Huawei’s Ascend chips and the MindSpore framework, and deployed a super-large computing cluster of over 100,000 cards.
More strategically significant is that GLM-5 did not stop at merely being “able to run” on a single platform; on the very first day of its release, it announced the completion of native deep adaptation to seven mainstream GPU ecosystems in China: Huawei Ascend, Moore Threads, Haiguang, Cambricon, Kunlun, TianShu Zhixin, and Suiruan.
This is not just simple code migration; it is a brutal reconstruction of the underlying system engineering.
Those familiar with the domestic chip ecosystem know that single-card computing power (TFLOPS) is often not the biggest bottleneck; the real barrier lies in the extremely weak communication bandwidth between chips and the incomplete software stack. To enable GLM-5 to achieve extreme efficiency on these chips, Zhiyuan’s engineering team delved deep into the CUDA kernel level, performing radical surgeries:
- Localized Distributed Parallel Strategies: In response to the disadvantage of insufficient interconnect bandwidth in domestic hardware, the team completely restructured the routing and partitioning strategies of tensor parallelism (TP), pipeline parallelism (PP), data parallelism (DP), and expert parallelism (EP), using algorithmic detours to significantly mask hardware communication shortcomings.
- INT4 Quantization Aware Training (QAT) Full Alignment: To break through the memory wall, GLM-5 introduced extremely aggressive INT4 quantization aware training during the supervised fine-tuning (SFT) phase. Even more hardcore, Zhiyuan even handwrote custom low-level quantization operators for these domestic chips, allowing the model to maintain almost lossless inference capabilities at extremely low precision.
- KV Cache Scheduling Limit Optimization: In response to the terrifying memory usage brought by long texts (200K), the team rewrote the memory management mechanism, cutting deployment costs in long sequence processing scenarios by 50%.
The results are shocking: after a series of crazy soft and hard collaborative optimizations, GLM-5’s throughput performance on a single domestic computing node can directly match that of a computing cluster composed of two international mainstream high-end GPUs (hinting at the H series).
This is not just a technical celebration for Zhiyuan alone. It signifies that China’s large model industry has evolved from “passively running overseas architectures on domestic cards” to “actively customizing full-stack system-level solutions based on the topology of domestic hardware, from architecture, algorithms, communication, to operators.” This is a true coming-of-age ceremony.
Commercial Restructuring and Dimensionality Reduction Strike: Token Economics That Shakes Silicon Valley
Technological breakthroughs ultimately need to reflect in commercial efficiency. The advent of GLM-5 has launched a dimensionality reduction strike against the existing global API market with an almost “brutal” pricing strategy.
Despite containing 744 billion parameters, the dual support of the MoE architecture and DSA sparse attention has compressed GLM-5’s inference costs to the extreme. Let’s look at a set of pricing data that directly determines the survival of developers:
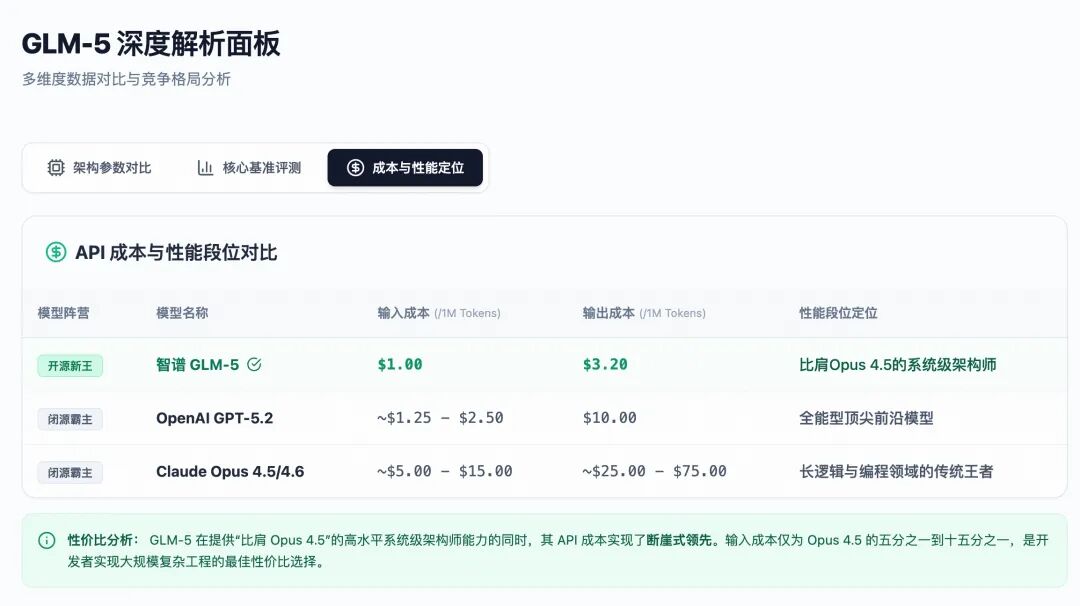
Data is cold and cruel. GLM-5 offers nearly equivalent hardcore programming and long-horizon agent capabilities to Claude Opus 4.5, yet its API call costs have been driven down to one-seventh or even one-tenth of its competitors!
This extreme cost-performance ratio has instantly ignited the global developer community. Since GLM-5’s integration into major mainstream programming tools (like Cursor, Roo Code, Claude Code, etc.), a massive influx of developers has surged in. Under the strong traffic impact, third-party cloud service providers like Ollama have experienced node overload.
In China, this fervor is even more direct. On February 12, due to the computing power demand far exceeding expectations, Zhiyuan officially released a price adjustment notice, announcing a structural price increase for the GLM Coding Plan package, with an overall increase starting from 30%, while the overseas version saw increases exceeding 100%. Even so, the daily limited subscription slots were still snapped up instantly, with countless developers setting alarms to grab them at 10 AM every day.
In a recent apology letter, Zhiyuan admitted that the surge in traffic led to capacity expansion not meeting expectations, and some users experienced throttling, proactively offering compensation and refund solutions. This “happy trouble” precisely proves the market’s extreme hunger for a cheap, high-quality intelligent model capable of executing complex engineering tasks.
Even more critically, GLM-5’s weights have been fully open-sourced under the MIT license on platforms like HuggingFace. This means that any startup, financial institution, or traditional enterprise with a certain computational foundation can deploy a supermodel with system architect capabilities privately on their intranet without paying high API “toll fees,” building an absolute data moat.
This undoubtedly serves as a heavy warning bell for Silicon Valley giants still mired in high inference costs and clinging to closed ecosystems.
Conclusion: An Irreversible Historical Tide
Zhiyuan GLM-5’s success proves three extremely important things to the world:
-
The main axis of AI development has shifted from “endless knowledge compression” to “rigorous system engineering.” Models that can draw, write poetry, and chat are now commonplace. The future that truly holds significant commercial leverage is represented by models like GLM-5, which can endure long asynchronous reinforcement learning cycles without collapsing, delve into codebases to fix bugs, and strategize in simulated business environments.
-
Open-source models are forcefully shattering the moat of closed-source models. When a 744B open-source model approaches the closed-source ceiling on hardcore leaderboards like SWE-bench, and its usage costs are merely one-tenth of the former, the infrastructure of large models as “utilities” has been thoroughly established.
-
China’s AI computing power ecology has completed the leap from “usable” to “well-used.” In the face of stringent sanctions, through architectural DSA sparsification, system-level Slime framework decoupling, and profound low-level operator optimization, Chinese AI teams have built a skyscraper on domestic sand.
As the bubble of “Vibe Coding” fades, the era of “Agentic Engineering” is gradually unfolding. GLM-5 is not only a dazzling business card handed to the world by Zhiyuan but also a thunderous declaration that domestic large models have officially taken over hardcore productivity.
For every developer, enterprise, and investor caught in this tide, it is no longer a matter of discussing whether “AI can replace me.” The only question is: how do you plan to redefine your productivity in this intelligent agent efficiency revolution initiated by GLM-5?
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.